1. 소개
웹 정보 바다라고 할 만큼 엄청난 양의 데이터를 가지고 있다. 트위터, 페이스북과 같은 사이트에서는 정규화된 JSON 형태의 데이터를 API로 제공해서 쉽게 원하는 데이터에 접근할 수 있다. 하지만, API를 통해서 제공되는 데이터는 제한적이고 원하는 데이터를 얻지 못할 수도 있다.
필요한 정보를 실제 사이트에서 직접 데이터를 추출해서 데이터를 가공할 필요가 있다. 이런 방식을 웹 크롤링(Web Crawling), 웹 스크래핑(Web Scraping)이라고 한다. 웹 크롤링은 웹 스파이터(spider), 봇(bot)이라고 해서 검색 엔진과 같은 여러 사이트(ex. 구글)에서 정보를 정기적으로 추출하는 방식이다. 웹 스크래핑은 웹 사이트에서 원하는 데이터를 추출하는 행위를 일반적으로 얘기한다. 둘의 차이점을 정리하면 아래와 같다.
- 웹 크롤링
- 검색 엔진에서 사용되며 bot과 같이 자동으로 웹 처리됨
- 다운로드한 사이트를 index하여 사용자가 빠르게 원하는 것을 검색할 수 있도록 해줌
- 웹 스크래핑
- 웹 사이트에서 원하는 데이터를 추출함
- 추출한 데이터를 원하는 형식으로 가공함
2. 웹 스크래핑
파이썬이 웹 스크래핑을 하는 데 가장 많이 사용된다. Nodejs에서도 Cheerio 모듈 을 사용해서 쉽게 원하는 데이터를 추출할 수 있지만, 본 포스트에서는 파이썬으로 웹 스크래핑하는 방법을 알아봅니다.
웹 스크래핑을 할 때는 3가지 정도의 단계를 거치게 된다.
- Scraping - 데이터 가져오기
- Parsing - 데이터 파씽
- Manipulation - 데이터 가공
먼저 필요한 파이썬 모듈을 설치하고 각 모듈의 사용법을 알아봅시다.
2.1 필요한 패키지 설치 및 사용방법
설치 방법은 맥 OS 기반으로 작성되었다.
- Beautiful Soup
- HTML과 XML 형식의 데이터를 보다 쉽게 파씽하고 다루는 모듈
- 현재 버전은 bs4
- urllib
- URL를 다루는 모듈
- 파이썬에 기본적으로 내장되어 있는 모듈임
- requests
- HTTP/1.1 요청를 보낼 수 있음
- 요청 내용에 헤더, 폼 데이터, multipart 파일과 parameter를 포함해서 보낼 수 있음
2.1.1 패키지 설치
파이썬 패키지 관리자 명령어(pip)로 필요한 패키지를 설치한다.
$ pip3 install beautifulsoup4
$ pip3 install requests
2.1.2 사용법과 예제
먼저 파이썬에 기본적으로 내장된 urllib 모듈을 사용해서 데이터를 가져와 보고 이어서 requests 모듈로 데이터를 가져오는 예제를 작성해봅니다. 전체 예제 소스는 github 에 작성되어 있다. 위키백과 사이트에서 요즘 화제 페이지의 주요 뉴스 정보를 가져오는 예제를 같이 작성해봅시다.
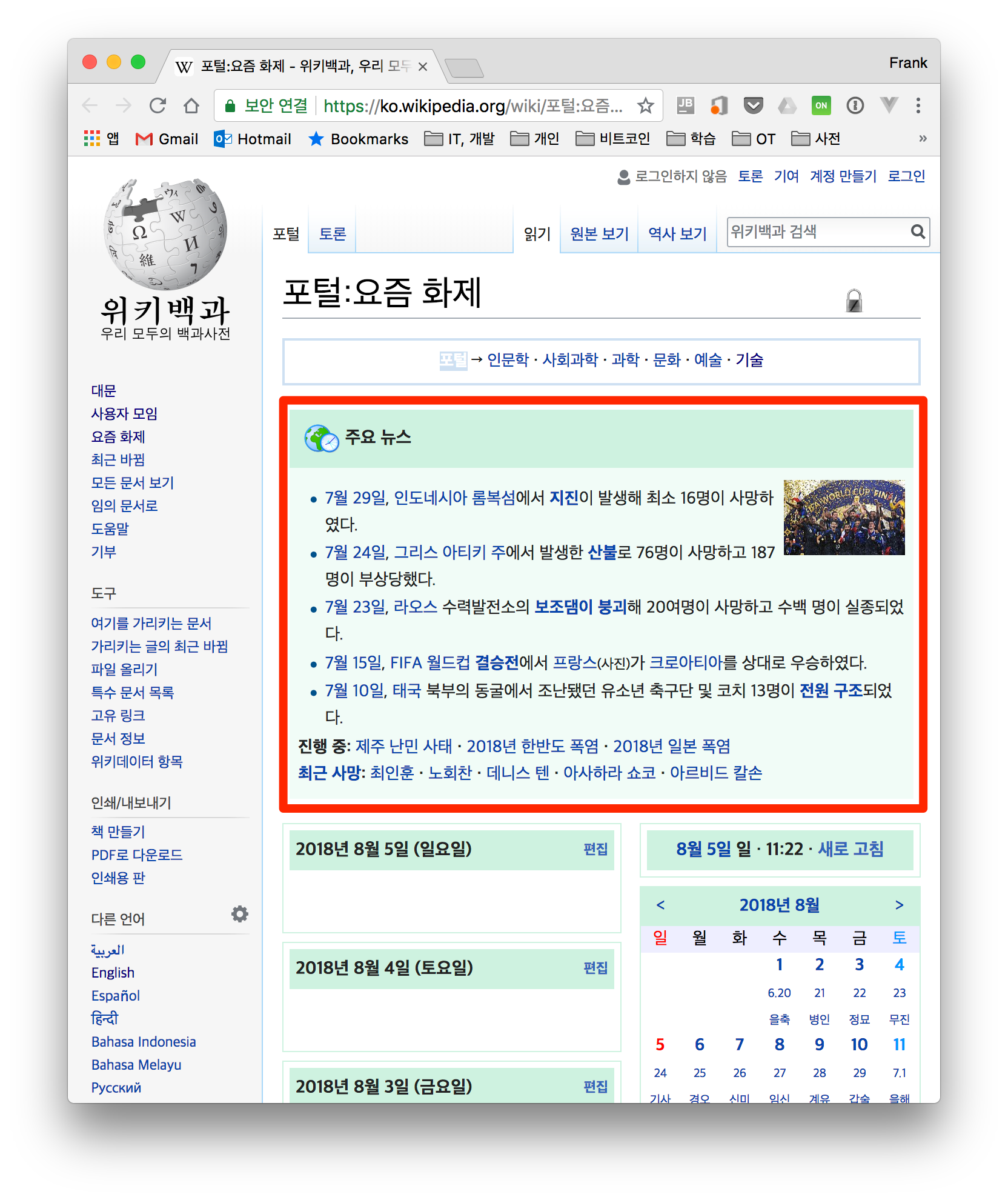
1. 크롬의 개발자 도구를 열어 원하는 부분의 태그를 확인한다.

2. 웹사이트에 접근하여 BeautifulSoup로 HTML를 파씽하고 원하는 데이터를 추출한다.
아래 코드는 urllib 모듈로 위키백과 사이트에 접근하는 방식이다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen(WIKI_URL) urllib로 html 가져오기
bsObj = BeautifulSoup(html, "html.parser")
main_news = bsObj.find("table", {"class": "vevent”}) 크롬에서 확인한 부분으로 작성함
다음은 urllib 모듈 대신 requests 모듈을 사용하여 html을 가져오는 방식이다. 스크립트를 작성하면 어쩔 수 없이 해당 웹 사이트에 자주 접속할 수 밖에 없는데, urlib 모듈로 접근하면 서버 로그에 urllib로 접속한다는 정보가 고스란히 남게 되고 또한 자주 접근하는 패턴으로 차단될 리스크가 있다. 하지만, requests 모듈은 headers에 추가 정보를 담아서 보낼 수 있어서 크롬이나 파이어폭스 브라우저가 보내는 정보를 담아서 보낼 수 있어 차단될 가능성이 적어 requests 모듈을 사용할 것을 추천한다. 블랙 리스트에 등록되는 것을 피하는 여러 방법은 다음 포스트에 구체적으로 다루도록 하자.
import requests
from bs4 import BeautifulSoup
session = requests.Session()
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit 537.36 (KHTML, like Gecko) Chrome",
"Accept": "text_html,application_xhtml+xml,application_xml;q=0.9,image_webp,**/**;q=0.8",
"Connection": "close"
}
bsObj = BeautifulSoup(session.get(WIKI_URL, headers=headers).content, "html.parser”) requests로 url에 접근해 html를 가져옴
main_news = bsObj.find("table", {"class": "vevent"})
HTML을 가져온 다음 BeautifulSoup에서 어떻게 파씽을 하고 원하는 데이터를 추출하는지 아래 코드를 보면서 알아봅시다.
bsObj = BeautifulSoup(html, "html.parser")
main_news = bsObj.find("table", {"class": "vevent"})
tr_all = main_news.find("table").find_all("tr")
# title
print(tr_all[0].get_text().strip())
# ui list
news_all = tr_all[1].find_all("li")
for each_tr in news_all:
text = each_tr.get_text().strip().replace("\n", " ")
striped_text = re.sub('\s\s+', " ", text)
print(striped_text)
라인 1에서는 파이썬에 기본으로 들어 있는 html.parser로 HTML를 파씽한다. lxml등과 같은 외부 파써도 사용할 수도 있다. (pip로 설치 필요) ex. bsObj = BeautifulSoup(html, ‘lxml’)
라인 2부터는 주요 뉴스를 포함하고 있는 vevent 클래스의 내용 전체를 먼저 얻어오고 한 번 더 tr 부분을 추출해 옵니다.
tr [0] - 메인 타이틀 tr [1] - 뉴스 내용
얻어온 태그 내용의 텍스트 부분을 추출하려면 get_text() 함수를 이용하고 불필요한 whitespace는 strip()나 replace()함수로 제거한다. 실행 결과는 다음과 같다.

3. 추가 예제
인터넷상에서 많은 데이터가 존재하기 때문에 웹 스크래핑 기술로 다양한 데이터를 만들어 낼 수 있다.
- 같은 한 제품의 가격에 대해 비교 할 수 있도록 스크래핑 (ex. 다나와)
- 여러 소셜 네트워크(ex. 트위터)에서 회사의 제품에 대한 feedback을 얻을 수 있도록 스크래핑
저는 개인적으로 리디북스 페이퍼(이북 리더기)에서 성경을 종종 읽고 싶어서 EPUB를 만들면 좋겠다고 생각을 했었다. 웹 스크래핑 기술을 익히고 나서 EPUB 포맷으로 변환하는 스크립트를 작성했다. 아이디어는 위 예제와는 크게 차이는 없다.
https://github.com/kenshin579/app-korean-catholic-bible
4. 정리
웹 스크래핑을 하다 보면 접속하는 사이트로부터 차단될 수 있어서, 어떻게 하면 차단 당하지 않고 웹 스크래핑할 수 있는지 다음 포스트(웹 스크래핑하면서 차단 방지하는 방법)에서 알아보도록 하죠.
5. 참고
조금 더 아래 책을 추천드립니다.
