1. What
ksqlDB (formerly Kafka SQL, KSQL)는 Kafka를 위한 스트리밍 SQL 엔진이다. SQL 인터페이스를 제공하고 있어 익숙한 SQL 구문으로 개발자들이 쉽게 Kafka에서 스트리밍 처리를 할 수 있게 도와준다. ksqlDB에서 제공하는 기능은 다음과 같다.
1.1 Feature
- 친숙하고 가벼운 SQL 구문을 통해 관계형 데이터베이스에 유사하게 접근하는 방식과 비슷하게 실시간 스트리밍 처리를 가능하다
- ksqlDB는 fault-tolerant, scale이 가능하도록 설계
- ksqlDB 내에서 Kafka Connect를 관리 기능을 제공
- 데이터 필터링, 변환, 집계, 조인, 윈도우 및 세션화를 포함하여 광범위한 스트리밍 작업을 위해 여러 함수 지원
- ex.
SUM,COUNT,UCASE,REPLACE,TRIM
- ex.
- KSQL 사용자 정의 함수도 구현 가능하도록 지원
- 람다 함수도 지원
참고
- https://docs.ksqldb.io/en/latest/developer-guide/ksqldb-reference/functions/
- https://docs.confluent.io/5.4.0/ksql/docs/developer-guide/udf.html
- https://docs.ksqldb.io/en/latest/how-to-guides/use-lambda-functions/
1.2 ksqlDB Architecture
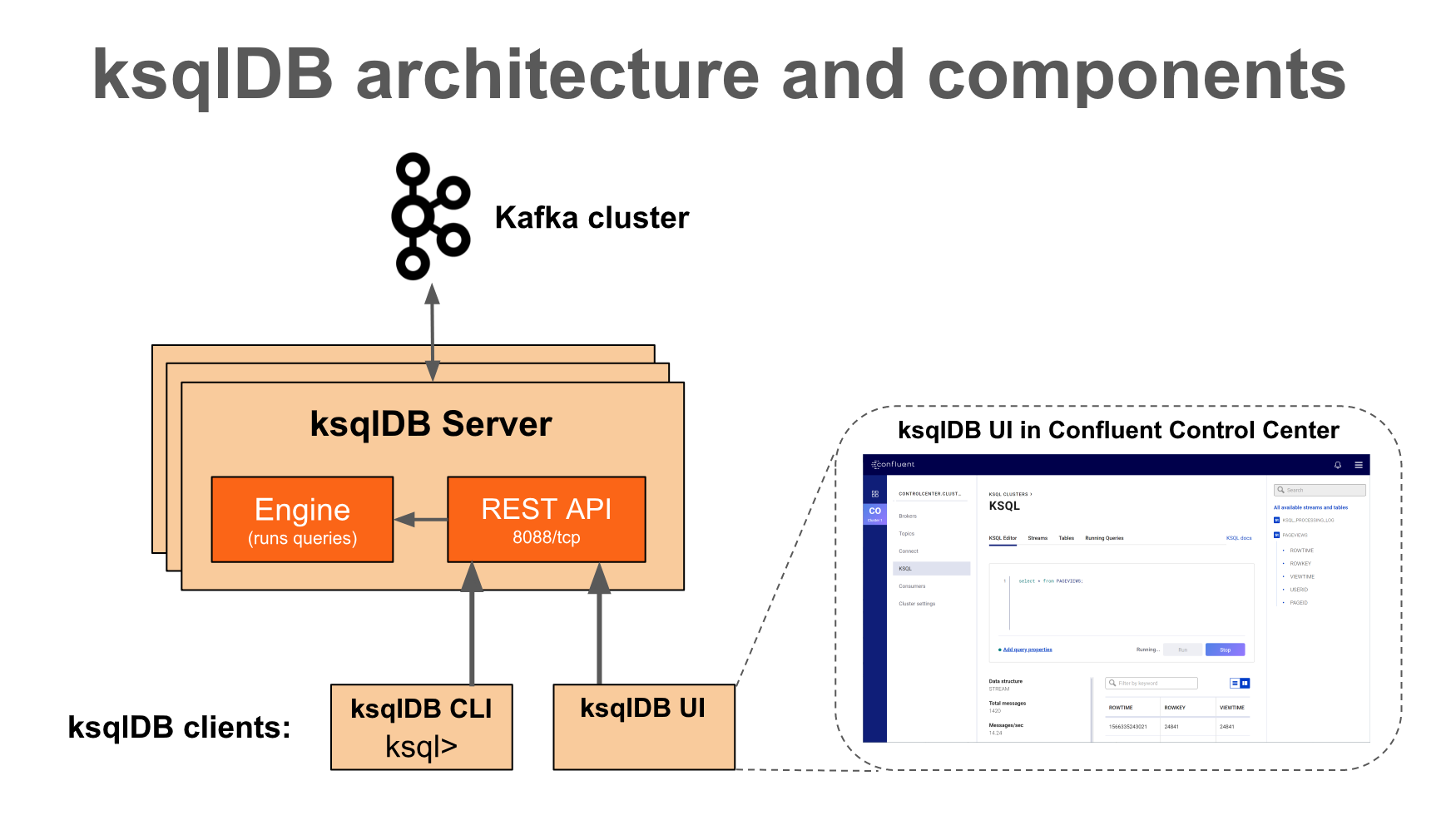
ksqlDB client
- ksqlDB CLI
- MySQL이나 PostgreSQL과 같은 console을 command interface (CLI)를 제공한다
- ksqlDB UI
- Control Center (유료 버전)는 Kafka 클러스터, 브로커, 토픽, Connector, ksqlDB 등을 포함한 주요 구성 요소를 한 곳에서 관리하고 모니터링할 수 있는 GUI 이다
REST Interface
- ksqlDB client가 ksqlDB Engine 에 접근하게 도와준다
ksqlDB Engine
- KSQL 구문과 쿼리를 실행한다
- 사용자는 KSQL 구문으로 어플리케이션 로직을 정의하고 엔진은 KSQL 구문을 파싱, 빌드해서 KSQL 서버에서 실행시킨다
- 각 KSQL서버들은 KSQL 엔진을 인스턴스로 실행시킨다
- 엔진에서는 RocksDB를 내부 상태 저장소로 사용된다
- ksqlDB는 Materialized View를 로컬로 디스크에 저장하는데 RocksDB를 사용한다
- RocksDB는 빠른 embedded key-value 저장소이고 library로 제공된다
"RocksDB는 Facebook에서 시작된 오픈소스 데이터베이스 개발 프로젝트로, 서버 워크로드와 같은 대용량 데이터 처리에 적합하고 빠른 저장장치, 특히 플래시 저장장치에서 높은 성능을 내도록 최적화되어 있다"
참고
- https://docs.confluent.io/5.4.3/ksql/docs/index.html
- https://docs.ksqldb.io/en/latest/operate-and-deploy/how-it-works/
- https://www.confluent.io/blog/ksql-streaming-sql-for-apache-kafka/
- https://docs.ksqldb.io/en/latest/tutorials/event-driven-microservice/
- https://github.com/confluentinc/ksql
- https://docs.ksqldb.io/en/latest/operate-and-deploy/how-it-works/
- https://www.confluent.io/blog/ksqldb-architecture-and-advanced-features/
- https://www.confluent.io/blog/ksqldb-pull-queries-high-availability/?_ga=2.35560801.1998071110.1666397521-1519298907.1666271761
- https://www.confluent.io/blog/how-to-tune-rocksdb-kafka-streams-state-stores-performance/
- https://www.datanami.com/2019/11/20/confluent-reveals-ksqldb-a-streaming-database-built-on-kafka/
- https://meeeejin.gitbooks.io/rocksdb-wiki-kr/content/overview.html
- https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams+Internal+Data+Management
- https://stackoverflow.com/questions/58621917/ksql-query-and-tables-storage
2. Why
ksqlDB를 왜 사용하면 좋은지 알아보아요.
2.1 Kafka 스트림 처리에 대한 3가지 방법

2.2 ksqlDB vs Kafka Streams
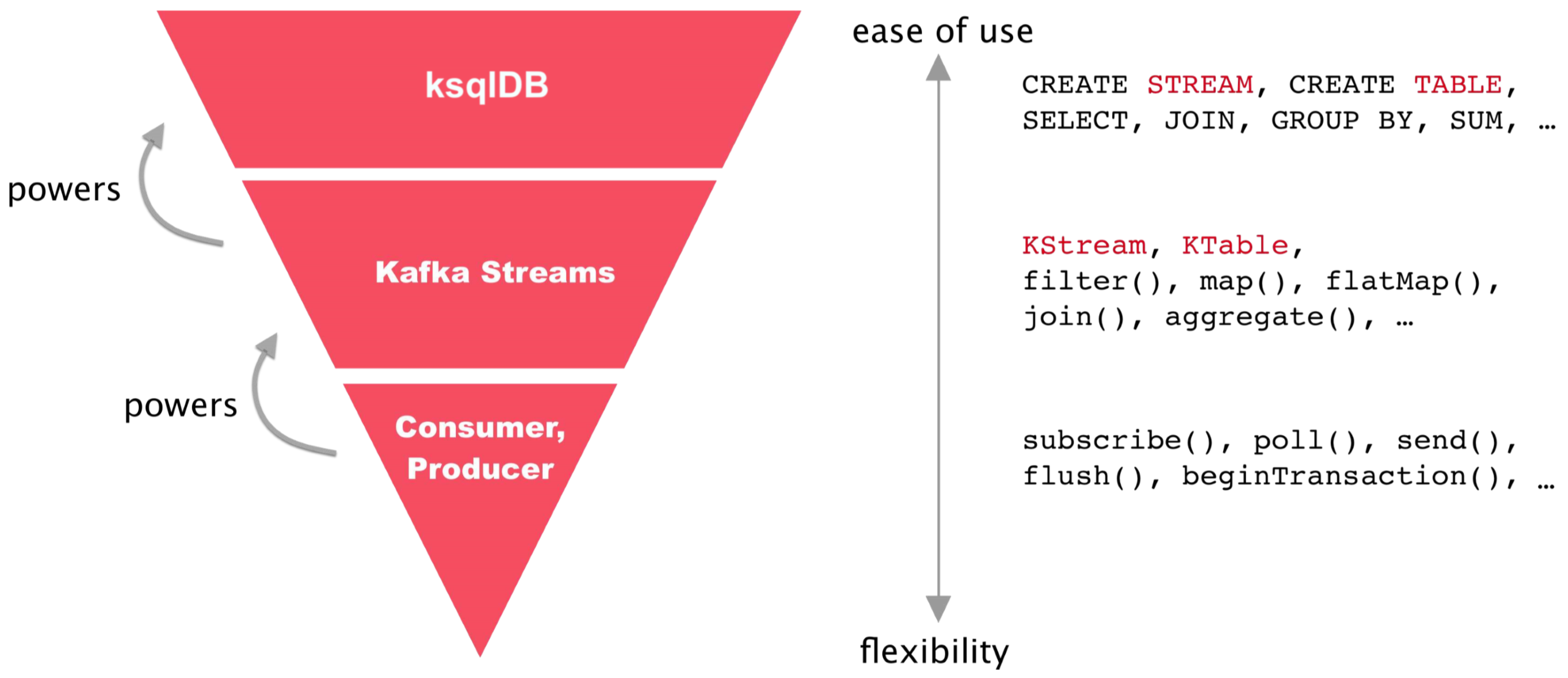
- ksqlDB
- Kafka Streams library 기반으로 개발되었다
- KSQL CLI interactive 하게 바로 스트리밍 처리를 확인해 볼 수 있다
- 익숙한 SQL 구문을 사용해서 빠르게 스트리밍 처리를 해 볼 수 있다
- Kafka Streams
- Kafka 기반의 스트리밍 처리를 할 수 있게 도와주는 라이브러리이다
- 더 복잡한 스트리밍 처리가 필요한 경우 Kafka Streams을 사용하는 게 더 좋을 수 있다
- ksqlDB와 비교했을 때 학습과 라이브러리에 대한 이해 및 경험치가 더 필요하다
참고
- https://engineering.linecorp.com/ko/blog/applying-kafka-streams-for-internal-message-delivery-pipeline/
- https://yooloo.tistory.com/m/115
- https://developer.confluent.io/tutorials/transform-a-stream-of-events/kafka.html#create-the-code-that-does-the-transformation
- https://laredoute.io/blog/why-how-and-when-to-use-ksql/
- https://www.slideshare.net/ConfluentInc/ksqldb-253336471
3. Who
ksqlDB는 Confluent 회사에 의해서 2017년부터 개발되었다.
3.1 History
Kafka
- 2010년 LinkedIn에서 내부 회사에서 발생하고 있는 이슈들을 해결하기 위해 만들어짐
- 2011년 Apache Kafka 오픈소스로 세상에 처음 공개
- 2014년 Confluent 회사 설립
- Kafka 공동 창시자가 LinkedIn을 나와서 새로운 회사를 설립
Kafka Connect
- 2015년 Kafka 0.9.0.0 release 버전에 포함
Kafka Stream
- 2016년 Kafka 0.10.0.0 release 버전에 포함
ksqlDB
- 2017년 KSQL Developer Preview로 공개
- 2019년 KSQL (Kafka SQL) -> ksqlDB 재브랜딩을 위해 새로운 이름으로 변경
참고
- https://docs.ksqldb.io/en/latest/operate-and-deploy/changelog/?_ga=2.211885267.679177078.1665747634-256754440.1665501546&_gac=1.60161119.1665905457.Cj0KCQjw166aBhDEARIsAMEyZh6DZ-g9fEdHzNf4ywXk1Oj2Q93_PLdfgAe_phLu9UaUpztGK_aOoFYaAsqyEALw_wcB
- https://docs.confluent.io/platform/current/installation/versions-interoperability.html#ksqldb
- https://dbdb.io/db/ksqldb
- https://www.buesing.dev/post/kafka-versions/
- https://www.linkedin.com/pulse/kafkas-origin-story-linkedin-tanvir-ahmed/
4. Where
다음과 같이 여러 회사에서 공식적으로 ksqlDB를 사용하고 있다. 국내에서는 LINE에서 ksqlDB를 이용해서 AB Test Report 시스템을 개선했다고 한다.
- Naver LINE
- AB Test Report
- 기존 시스템 구조에서는 Redis에 저장된 event log를 가져와 join window를 구현함
- ksqlDB를 사용해서 아키텍쳐가 단순화됨 (join two streams without redis)
- ticketmaster - 티켓 판매 회사
- Nuuly - 옷 렌탈 및 재판매 서비스
- ACERTUS - 자동차 픽업/배달 서비스
- optimove - CRM 마케팅 소프트웨어 (w/ AI)를 서비스로 개발 및 판매하는 비상장 회사
- Bosch: 자동차 및 산업 기술, 소비재 및 빌딩 기술 분야의 선도적 기업
- Voicebridge: voice-based systems for rural populations in developing countries that lack internet access



참고
5. How
5.1 Installation on local-machine
로컬환경에서 쉽게 여러 Kafka 구성요소를 구동하기 위해 docker-compose로 실행한다. 먼저 docker-compose.yml 파일을 다운로드한다.
$ curl --output docker-compose.yml \
https://raw.githubusercontent.com/kenshin579/tutorials-go/master/kafka/confluent/docker-compose.yml
Confluent Platform stack을 시작시킨다.
$ docker-compose up -d
KSQL Interactive CLI 시작하기
$ docker exec -it ksqldb-cli ksql http://ksqldb-server:8088
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
===========================================
= _ _ ____ ____ =
= | | _____ __ _| | _ \| __ ) =
= | |/ / __|/ _` | | | | | _ \ =
= | <\__ \ (_| | | |_| | |_) | =
= |_|\_\___/\__, |_|____/|____/ =
= |_| =
= The Database purpose-built =
= for stream processing apps =
===========================================
Copyright 2017-2022 Confluent Inc.
CLI v7.2.2, Server v7.2.2 located at http://ksqldb-server:8088
Server Status: RUNNING
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>
5.2 KSQL Usage
예제를 통해서 조금 더 ksqlDB에 대해서 알아보자.
5.3 Collections : Stream vs Table
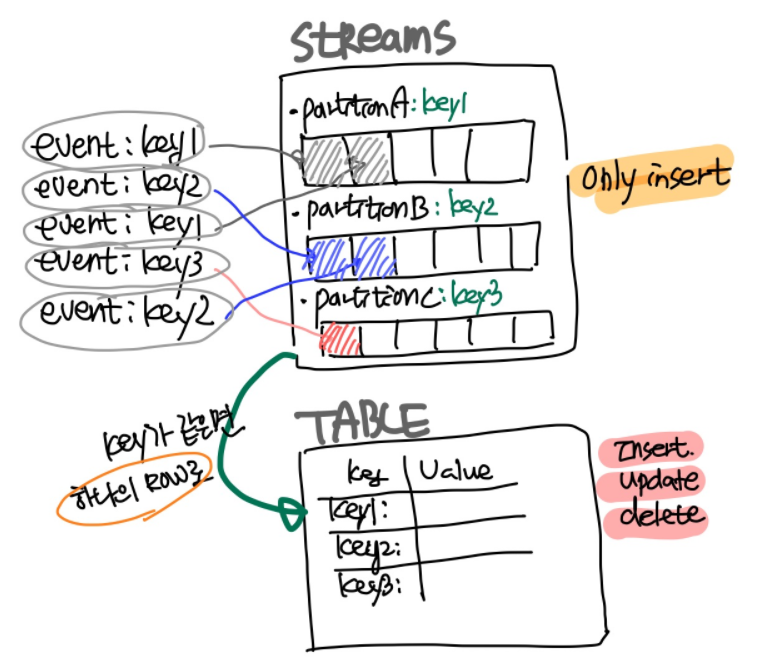
5.3.1 Stream
-
영속적으로 무제한의 스트리밍 되는 이벤트 컬렉션이다
- Partition으로 데이터가 관리
-
Row는 일단 생성된 후에는 변경이 불가능하다 (immutable, append-only)
- 각 Row는 특정 partition에 저장된다
- INSERT만 가능하다
-
Stream, Table 또는 Kafka Topic에서 새 Stream를 생성할 수 있다
# 기존 Kafka topic에서 Stream을 생성하거나 Topic이 없는 경우에는 자동 생성된다
ksql> CREATE STREAM riderLocations (profileId VARCHAR, latitude DOUBLE, longitude DOUBLE)
WITH (kafka_topic='locations', value_format='json', partitions=1);
# 다른 Stream에서 새로운 Stream을 생성할 수 있다
ksql> CREATE STREAM myCurrentLocation AS
SELECT profileId,
latitude AS la,
longitude AS lo
FROM riderlocations
WHERE profileId = 'c2309eec'
EMIT CHANGES;
kafka_topic- 기존 Kafka topic에서 Stream을 생성하거나 Topic이 없는 경우에는 자동 생성된다value_format- Kafka topic에 저장된 메시지의 인코딩 방식을 지정한다partitions- Kafka topic의 partition 수를 지정한다
5.3.2 Table (Materialized view)
- Table 데이터는 현재 최신 상태를 가지고 mutable한 이벤트 컬렉션이다
- Row는 변경 가능하며 Primary Key가 있어야 한다
- INSERT, UPDATE, DELETE이 가능하다
- Stream, Table 또는 Kafka Topic 에서 새 Table 생성 가능하다
# rider 들의 최신 위치를 추적하는 materialized view를 생성한다
ksql> CREATE TABLE currentLocation AS
SELECT profileId,
LATEST_BY_OFFSET(latitude) AS la,
LATEST_BY_OFFSET(longitude) AS lo
FROM riderlocations
GROUP BY profileId
EMIT CHANGES;
# 라이더가 주어진 위치에서 얼마나 떨어져 있는지 확인하는 table을 생성한다
ksql> CREATE TABLE ridersNearMountainView AS
SELECT ROUND(GEO_DISTANCE(la, lo, 37.4133, -122.1162), -1) AS distanceInMiles,
COLLECT_LIST(profileId) AS riders,
COUNT(*) AS count
FROM currentLocation
GROUP BY ROUND(GEO_DISTANCE(la, lo, 37.4133, -122.1162), -1);
LATEST_BY_OFFSET- 특정 column의 최신 값을 반환하는 aggregate 함수이다
EMIT CHANGES- EMIT CHANGES 절을 추가하면 모든 변경 사항을 지속적으로 받을 수 있다
COLLECT_LIST(col1)- col1의 모든 값을 포함한 array를 반환한다
참고
5.4 Query
5.4.1 Push Query (Continuous Query)
- Push query는 실시간 변경 되는 결과를 구독할 수 있다
- EMIT 절은 쿼리를 영속적으로 계속 실행시킨다
- CLI에서 시작한 push query를 종료하려면
ctrl+C를 눌러야 한다
# Stream의 데이터를 지속적으로 조회하고 쿼리가 계속 실행된다
ksql> SELECT * FROM riderLocations
WHERE GEO_DISTANCE(latitude, longitude, 37.4133, -122.1162) <= 5 EMIT CHANGES;
# Table의 데이터를 지속적으로 조회하고 쿼리가 계속 실행된다
ksql> SELECT * FROM currentLocation EMIT CHANGES;
ksqlDB에 실제 데이터를 넣어보자. 아래는 riderLocations stream에 insert 하는 거라 riderLocations와 연관된 Kafka Topic에 publish 하는 것과 같다.
ksql> INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('c2309eec', 37.7877, -122.4205);
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('18f4ea86', 37.3903, -122.0643);
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('4ab5cbad', 37.3952, -122.0813);
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('8b6eae59', 37.3944, -122.0813);
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('4a7c7b41', 37.4049, -122.0822);
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('4ddad000', 37.7857, -122.4011);
Kafka CLI 명령어로도 publish 할 수 있다.
$ kafka-console-producer.sh --bootstrap-server localhost:9092 --topic locations
> {"profileId": "c2309ee5", "latitude": 42.7877, "longitude": -122.4205}
5.4.2 Pull Query (Classic Query)
- Pull Query는 테이블의 현재 상태를 가져온다
# 현재 Mountain View에서 10 마일 이내에있는 모든 라이더를 검색
ksql> SELECT * from ridersNearMountainView WHERE distanceInMiles <= 10;
참고
-
https://www.rittmanmead.com/blog/2017/10/ksql-streaming-sql-for-apache-kafka/
-
https://docs.ksqldb.io/en/latest/concepts/time-and-windows-in-ksqldb-queries/
5.5 Control Center
지금까지 CLI에서만 ksqlDB를 사용해 보았는데요. Control Center에서도 ksqlDB를 사용해보자. http://localhost:9021 에 접속한다.
5.6 Datagen Source Connector
Datagen Source Connector는 개발 및 테스트를 위해 Mock 데이터를 생성해주는 connector이다. 설정한 값에 따라서 주기적으로 데이터를 생성해주어 연속적으로 데이터를 계속 받는 시뮬레이션이 가능하다.
5.6.1 Generate Mock Data
pageviews와 users를 mock으로 생성한다.
Connect > Add Connector 버튼 클릭 > DatagenConnector 선택이후 아래 정보를 입력한다.
# pageviews mock 데이터 생성
{
"name": "datagen-pageviews",
"config": {
"name": "datagen-pageviews",
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"kafka.topic": "pageviews",
"max.interval": "100",
"quickstart": "pageviews"
}
}
# users mock 데이터 생성
{
"name": "datagen-users",
"config": {
"name": "datagen-users",
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"kafka.topic": "users",
"max.interval": "1000",
"quickstart": "users"
}
}
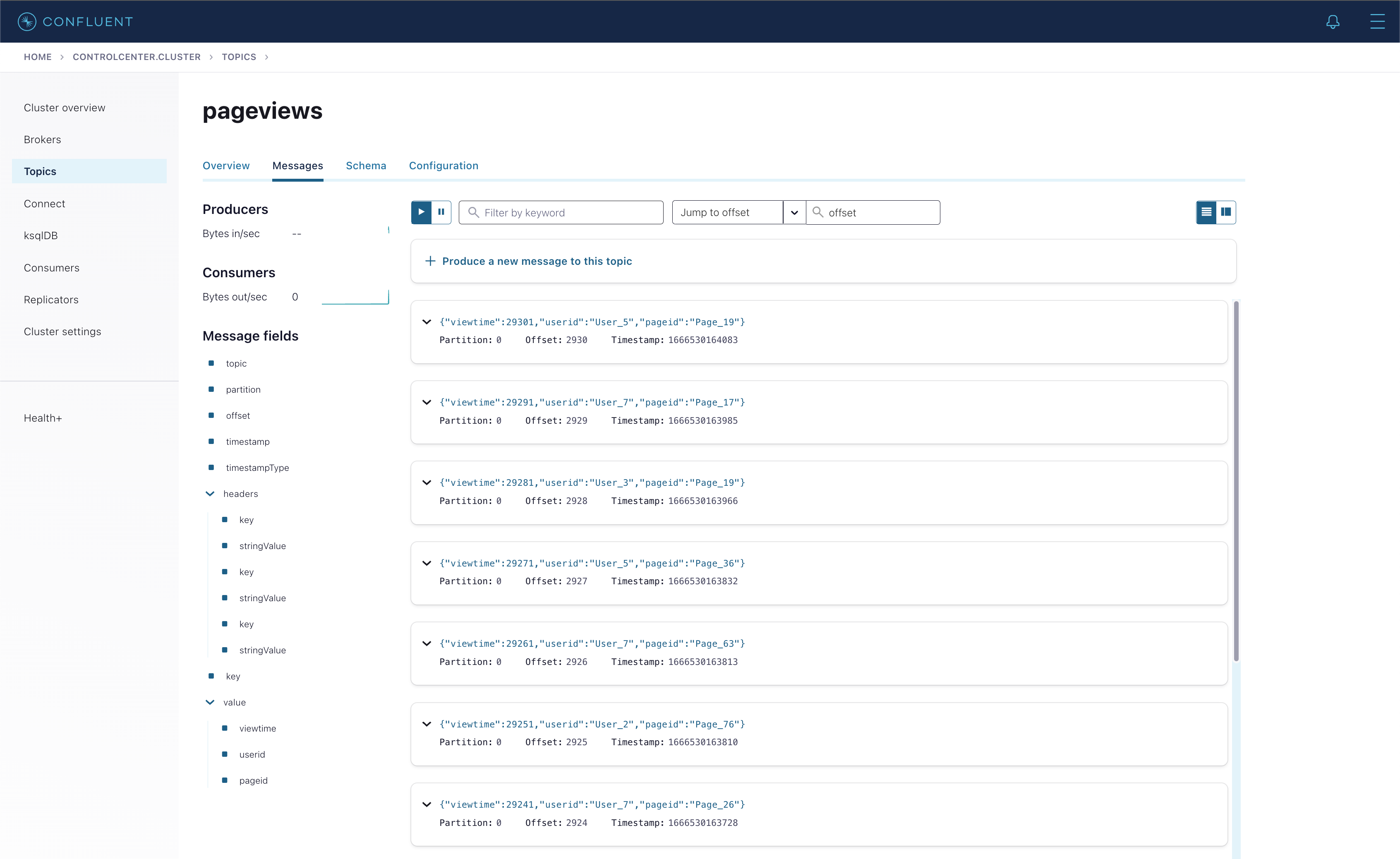
Topics > pageviews 클릭 > Messages 탭 클릭해보자. pageviews topic에 실시간으로 데이터가 publish되고 있는 것을 확인할 수 있다.
참고
- https://docs.confluent.io/kafka-connectors/datagen/current/index.html#datagen-source-connector-for-cp
- https://always-kimkim.tistory.com/entry/kafka-develop-kafka-connect-datagen
- https://www.confluent.io/blog/easy-ways-generate-test-data-kafka/
- https://github.com/confluentinc/kafka-connect-datagen/tree/master/src/main/resources
5.7 Joins Collections
ksqlDB의 Join와 기존 관계형 데이터베이스의 Join는 둘 이상의 데이터를 합친다는 점에서 비슷하다. Join 구문 사용해서 실시간으로 발생하는 streams 이벤트를 병합할 수 있다.
# 1.create stream
ksql> CREATE STREAM pageviews_stream
WITH (KAFKA_TOPIC='pageviews', VALUE_FORMAT='AVRO');
# 2. create table
ksql> CREATE TABLE users_table (id VARCHAR PRIMARY KEY)
WITH (KAFKA_TOPIC='users', VALUE_FORMAT='AVRO');
pageviews stream과 users table을 join해서 user_pageviews를 생성한다.
# user_pageviews는 USER_PAGEVIEWS topic이 생성이 된다
ksql> CREATE STREAM user_pageviews
AS SELECT users_table.id AS userid, pageid, regionid, gender
FROM pageviews_stream
LEFT JOIN users_table ON pageviews_stream.userid = users_table.id
EMIT CHANGES;
# user_pageviews stream에서 regionId가 8, 9로 끝나는 별도 pageviews를 생성
ksql> CREATE STREAM pageviews_region_like_89
WITH (KAFKA_TOPIC='pageviews_filtered_r8_r9', VALUE_FORMAT='AVRO')
AS SELECT * FROM user_pageviews
WHERE regionid LIKE '%_8' OR regionid LIKE '%_9'
EMIT CHANGES;
5.8 Windows
5.8.1 Time
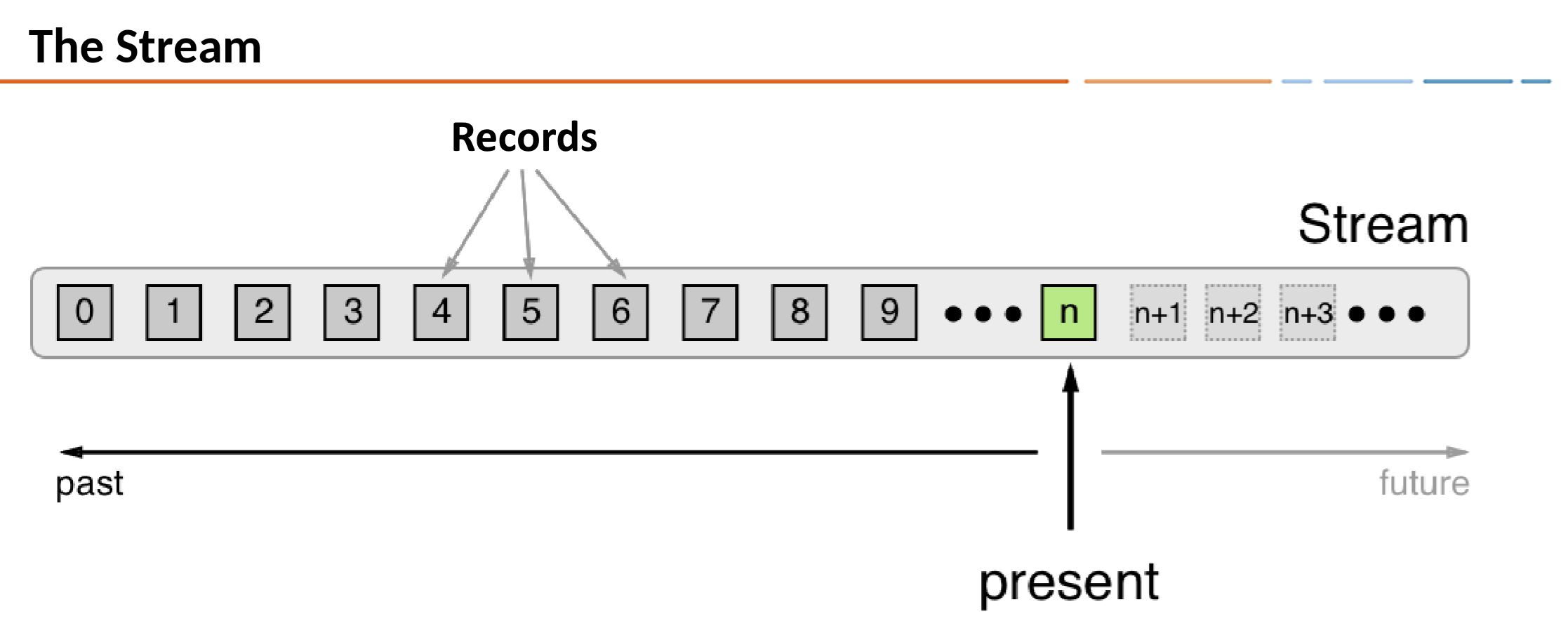
- 각 Record에는 timestamp가 들어가 있다
- Timestamp는 producer 어플리케이션이나 Kafka broker에 의해서 설정된다
- Timestamp는 aggregation, join와 같은 시간 의존적인 작업에서 사용된다
5.8.2 Window
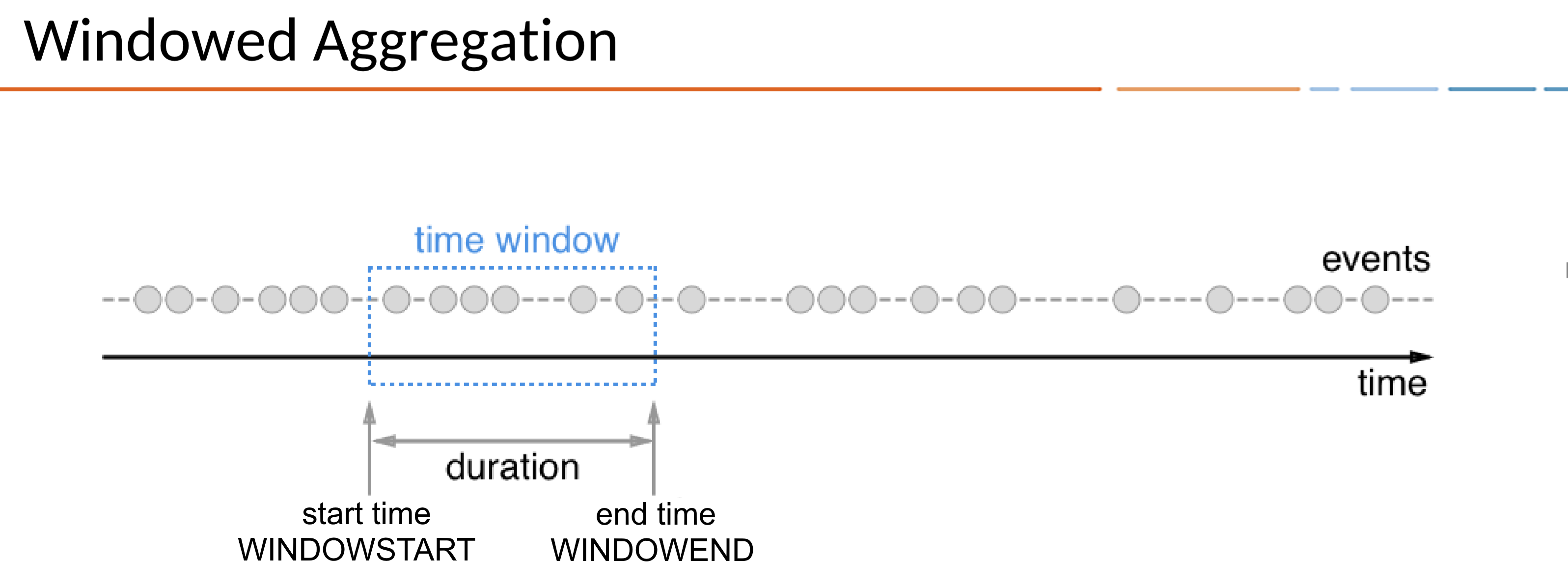
- ksqlDB는 스트림을 이용해서 특정 기간(Window)의 이벤트를 집계해서 보내주는 형태의 Window 쿼리를 제공한다
- 특정 기간을 Duration으로 나타내고, Duration은
WINDOWSTART/WINDOWEND로 표현할 수 있다 WINDOWSTART/WINDOWEND는 Window 쿼리를 생성하면 SELECT 절에 선언해서 사용할 수 있다
5.8.3 Window Types
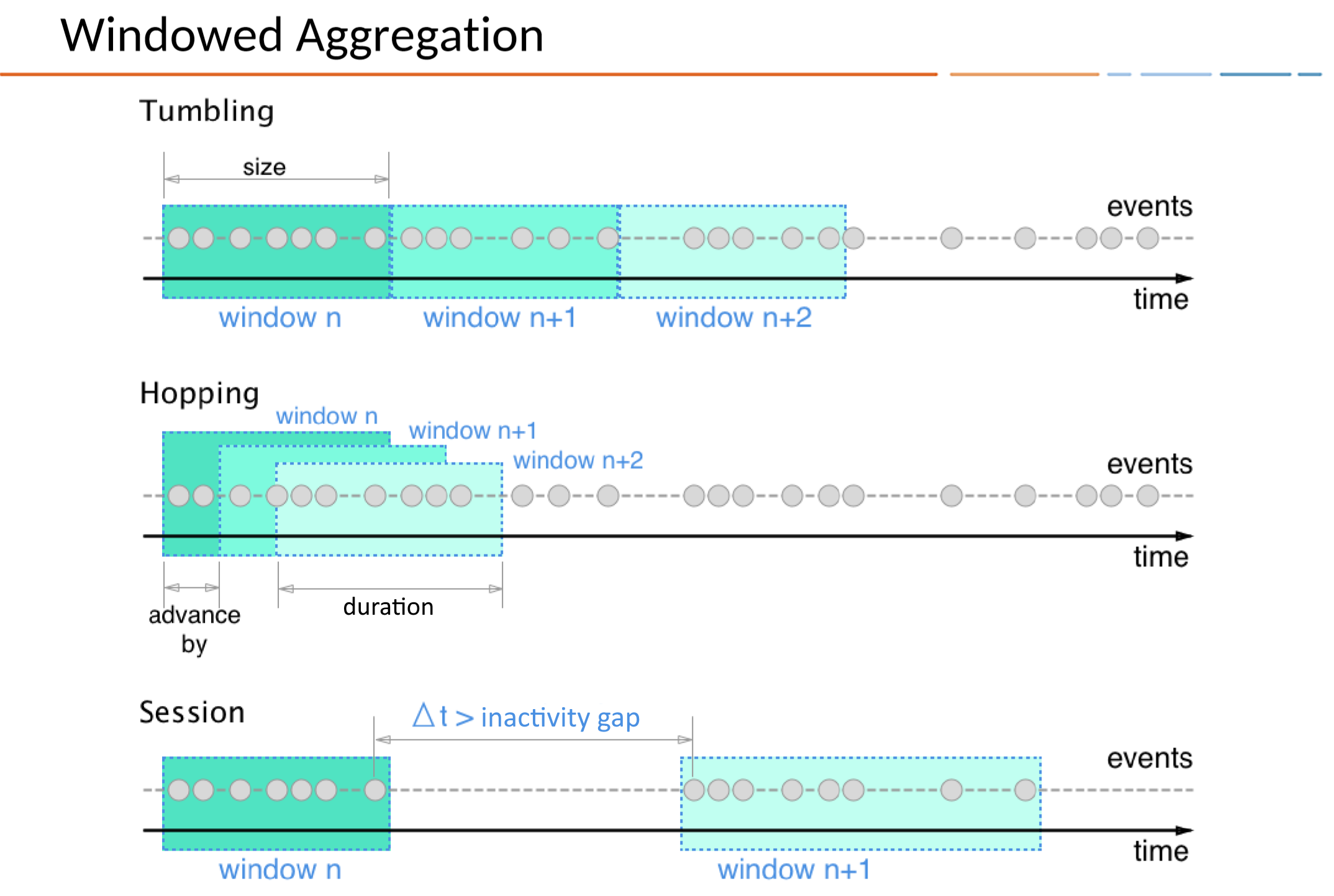
KSQL에서 Time Windows을 정의하는 3가지 방법이 있다.
- Tumbling
- Time-based
- Fixed-duration, non-overlapping, gap-less windows
- ex.
WINDOW TUMBLING (SIZE 1 HOUR)
- Hopping
- Time-based
- Fixed-duration, overlapping windows
- ex.
WINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECOND)
- Session
- Session-based
- Dynamically-sized, non-overlapping, data-driven windows
- Inactivity gap 값으로 활동이 있는 구간을 구분하여 Session Window를 생성한다
- Session Window는 사용자 행동 분석(ex. 사용자 방문자 수)에 특히 유용하게 사용할 수 있다
- ex.
WINDOW SESSION (60 SECONDS)
# 30초인 텀블링 창에서 영역 8과 9의 페이지뷰 수를 계산하는 pageviews_per_region_89라는 Table을 생성
ksql> CREATE TABLE pageviews_per_region_89 WITH (KEY_FORMAT='JSON')
AS SELECT userid, gender, regionid, COUNT(*) AS numusers
FROM pageviews_region_like_89
WINDOW TUMBLING (SIZE 30 SECOND)
GROUP BY userid, gender, regionid
HAVING COUNT(*) > 1
EMIT CHANGES;
ksql> SELECT * FROM pageviews_per_region_89 EMIT CHANGES;
참고
5.9 REST API
$ curl --location --request POST 'http://localhost:8088/ksql' \
--header 'Content-Type: application/json' \
--data-raw '{
"ksql": "show streams;",
"streamProperties":{}
}'
[
{
"@type": "streams",
"statementText": "show streams;",
"streams": [
{
"type": "STREAM",
"name": "RIDERLOCATIONS",
"topic": "locations",
"keyFormat": "KAFKA",
"valueFormat": "JSON",
"isWindowed": false
},
...생략...
{
"type": "STREAM",
"name": "USER_PAGEVIEWS",
"topic": "USER_PAGEVIEWS",
"keyFormat": "KAFKA",
"valueFormat": "AVRO",
"isWindowed": false
}
],
"warnings": []
}
]
ksqlDB 서버는 REST API를 제공하고 있고 API 전체 문서는 아래 링크를 참고해주세요.
- https://rmoff.net/2019/01/17/ksql-rest-api-cheatsheet/
- https://docs.ksqldb.io/en/latest/developer-guide/api/
5.10 Connector Management
Kafka Connector는 여기를 참고해주세요
ksqlDB는 2가지 모드로 connector를 실행할 수 있다. 모드에 따라서 connector 어떻게 어디에서 실행할지를 결정한다.
- Embedded
- Embedded 모드에서는 ksqlDB는 서버에서 직접 connector를 실행한다
- External
- 이 모드는 외부 Kafka Connect 클러스터와 통신하는 방식이다
ksql> CREATE SINK CONNECTOR `mongodb-test-sink-connector` WITH (
"connector.class"='com.mongodb.kafka.connect.MongoSinkConnector',
"key.converter"='org.apache.kafka.connect.json.JsonConverter',
"value.converter"='org.apache.kafka.connect.json.JsonConverter',
"key.converter.schemas.enable"='false',
"value.converter.schemas.enable"='false',
"tasks.max"='1',
"connection.uri"='mongodb://MongoDBIPv4Address:27017/admin?readPreference=primary&appname=ksqldbConnect&ssl=false',
"database"='local',
"collection"='mongodb-connect',
"topics"='test.topic'
);
참고
- https://medium.com/@rt.raviteja95/mongodb-connector-with-ksqldb-with-confluent-kafka-2a3b18dc4c25
- https://docs.ksqldb.io/en/latest/how-to-guides/use-connector-management/
5.11 KSQL Library
- golang
- java
6. When
ksqlDB는 Kafka 기반으로 데이터를 처리하기 때문에 실시간으로 데이터를 변환, 통합 및 분석이 즉시 필요한 곳에 사용한다. 아래와 같이 다양한 분야에서 사용될 수 있다.
- 이상 징후 및 패턴 감지
- 실시간 분석
- 예측 분석
- 물류 및 IoT 관리
- 실시간 경고 및 알림
- 인프라 현대화
- Customer 360
- 사이버 보안
참고
- https://developer.confluent.io/tutorials/
- https://blog.voidmainvoid.net/227
- https://github.com/confluentinc/ksql/tree/0.1.x/docs#ksql-documentation
- https://www.confluent.io/blog/stream-processing-vs-batch-processing/
7. FAQ
ksqlDB 다양한 FAQ는 아래를 참고해주세요.
7.1 ksqlDB의 License는 Apache License 2.0인가?
- Apache License는 아니다
- ksqlDB는 Confluent Community License가 부여되었고 Confluent 회사 제품으로 관리되고 있다
7.2 Confluent Community License는 어떤 제약이 있나?
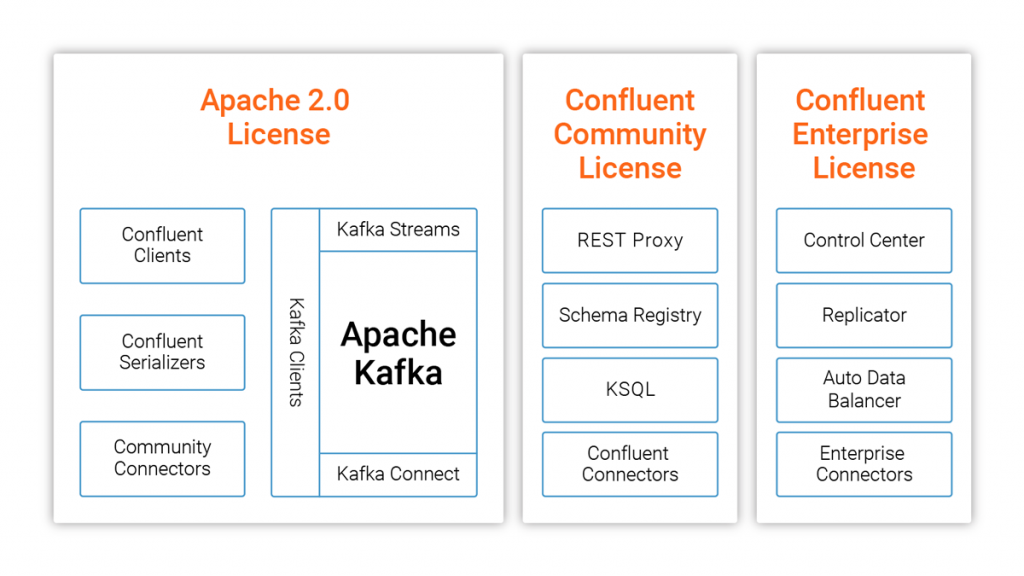
- ksqlDB을 사용해서 Confluent에서 제공하는 형태의 서비스만 제공하지 않으면 사용할 수 있는 것 같다
- KSQL 자체가 제공되는 제품인 SaaS 제품으로 제공되면 안된다
- 회사 내부 프로젝트에 사용하려면, 사용전에 라이센스 검토가 필요할 것으로 판단된다
- https://www.confluent.io/confluent-community-license-faq/
- https://www.confluent.io/ko-kr/blog/license-changes-confluent-platform/
8. Wrap up
ksqlDB는 이미 우리에게 익숙한 SQL 구문으로 Kafka에서 스트리밍 처리를 쉽게 할 수 있도록 도와준다.
몇개 안되는 Stream과 Table 생성의 경우에 충분히 Control Center 나 CLI에서 생성해서 사용할 수 있지만, 여러 Stream간의 Pipeline이 필요한 경우에는 보다 쉽게 사용할 수 Stream Designer UI를 사용해보면 좋을 것 같다.
-
Visual Builder for Streaming Data Pipeline
-
Confluent Cloud에서 제공
-
https://www.confluent.io/blog/building-streaming-data-pipelines-visually
9. Reference
-
ksql syntax
-
ksql
- https://ksqldb.io/quickstart.html?utm_source=thenewstack&utm_medium=website&utm_content=inline-mention&utm_campaign=platform
- https://always-kimkim.tistory.com/entry/kafka101-ksql
- https://www.rittmanmead.com/blog/2017/10/ksql-streaming-sql-for-apache-kafka/
- https://www.confluent.io/blog/intro-to-ksqldb-sql-database-streaming/
- https://docs.confluent.io/platform/current/platform-quickstart.html#ce-quickstart?utm_source=github&utm_medium=demo&utm_campaign=ch.examples_type.community_content.cp-quickstart
- https://github.com/confluentinc/demo-scene/blob/master/introduction-to-ksqldb/demo_introduction_to_ksqldb_01.adoc
- https://www.confluent.io/blog/guide-to-stream-processing-and-ksqldb-fundamentals/
- https://hevodata.com/learn/kafka-ksql-streaming-sql-for-kafka/